We’ve been listening to our customers. Whether you’re a SolarWinds® Loggly® or SolarWinds AppOptics™ user, we’ve been working hard to make your life easier. We’re happy to announce a brand-new experience that brings together metrics, traces, and logs in a single platform, making it faster and easier to troubleshoot application and infrastructure issues.
Metrics, Traces, and Logs for Everyone
As applications get more complex, it becomes increasingly important to have visibility across all aspects of how applications are performing. It’s now commonplace to use three different types of data to understand and validate application performance: metrics, traces, and logs. Let’s look at how these can help us.
Metrics
These are time series measurements used to monitor trends and deliver a high-level view into application performance. Key metrics include response time latency, error rate, request volume, and resource consumption metrics of the underlying infrastructure such as CPU and memory utilization. It’s also important to monitor other resource metrics on the supporting infrastructure, such as CPU saturation in containers, virtual machines, and databases. Queue lengths are another important metric to watch in more complex data pipelines to monitor for backpressure that can eventually lead to slowdown, data loss, or other production issues.
Traces
Traces contain detailed information about a specific request. Traces can span multiple services and containers and show information such as the resource requested, how long did the request take, where did it spend its time (down to the function in each service), and which parts of the infrastructure were dependencies of the request. Traces can now be directly linked with logs as well to quickly have full context without guessing for related events.

Logs
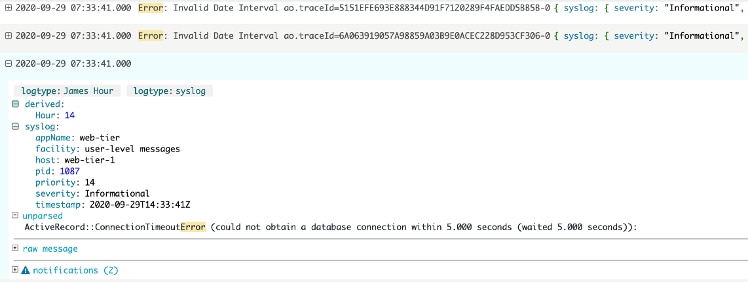
Logs and events contain rich information to help us get a full understanding of an issue. Default log messages generated by applications and associated infrastructure are useful to identify glaring errors, resource constraints such as thread exhaustion in an application, or timeouts from a database. The custom logging developers add to their applications is priceless. It’s good practice to handle exceptions in an application and log a message of possible causes when you’re developing the application. This allows operations teams gain context from the developer when solving issues even years down the road.
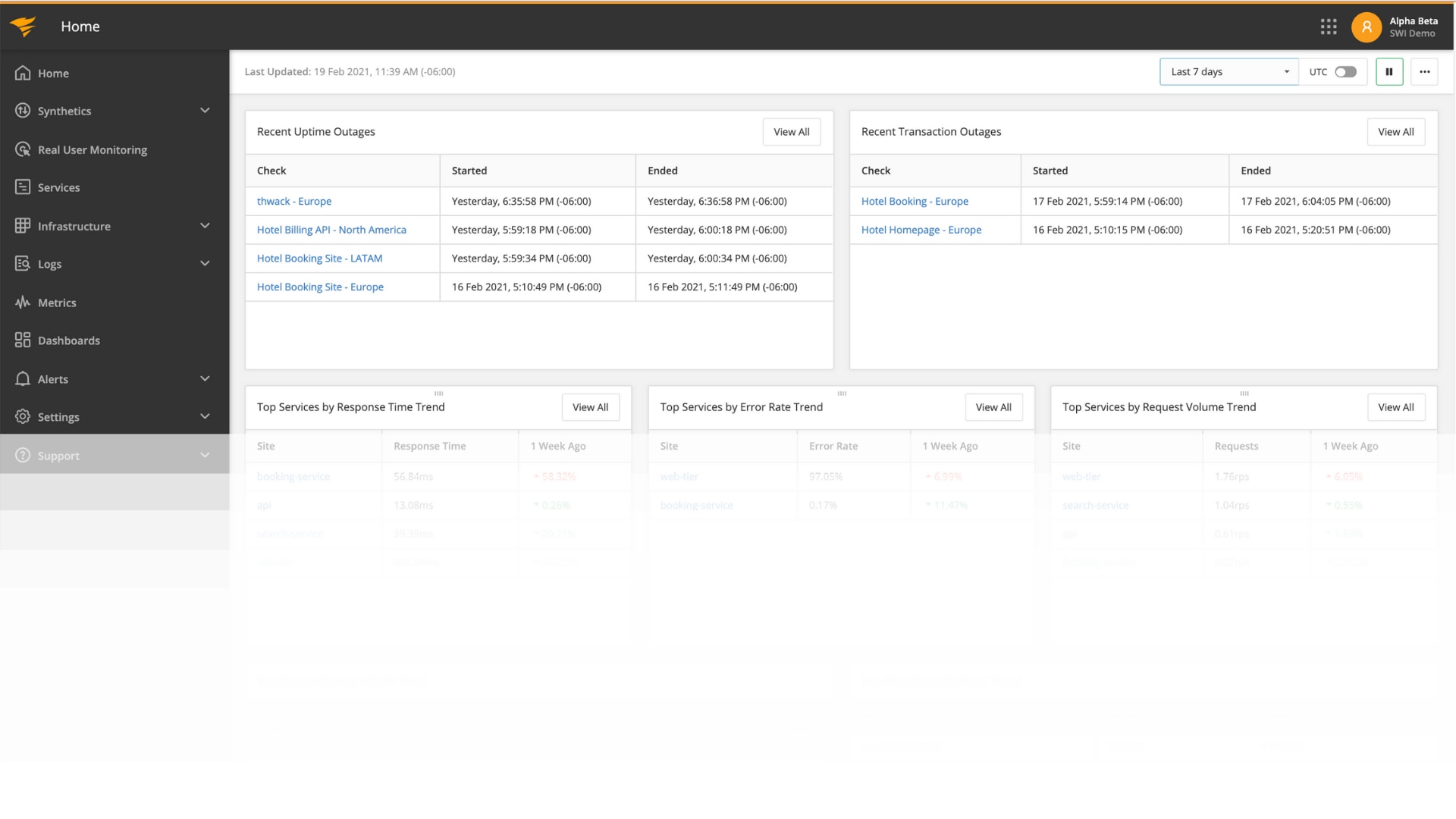
How Does It Work?
The new APM Integrated Experience brings together AppOptics and Loggly, so metrics, traces, and logs can be viewed using a single interface. The main navigation includes:
- Home—A new landing page with a high-level view of what’s changed in the last week and what could be an issue.
- Dashboards—Dashboards for both metrics and logs
- Services—APM data containing summary views and detailed distributed traces
- Infrastructure—Lists for hosts and containers, plugins for web servers and databases, and direct integrations for AWS and Azure
- Logs—Advanced searching capabilities on structured logs and a Dynamic Field Explorer™
- Metrics—Explore monitored time series; helpful for rapid troubleshooting
This Sounds Great, But How Do I Use This in the Real World?
Application performance issues are often caused by the underlying database, so let’s walk through an example of how we can catch application-impacting common database issues and quickly understand their impact.
Example situation:
Database is returning “MySQL has gone away” because the server is under too much load and queries are timing out.
In this situation, the latency for applications making queries to this database would have already been increasing as the latency due to slow queries increased. This increased application latency could have triggered an alert, and then looking at associated traces would show the database was the underlying bottleneck. We could then look at the CPU and memory metrics for the database to understand it was under too much load. Using this information, this incident could have been prevented before any requests errored due to the database timeouts.
If we didn’t catch the issue using metrics and we were instead responding to elevated error rates in the application or database, the “MySQL has gone away” messages from the logs along with the error messages in the traces would quickly identify what’s happening, helping get to resolution faster.
How Do I Try It?
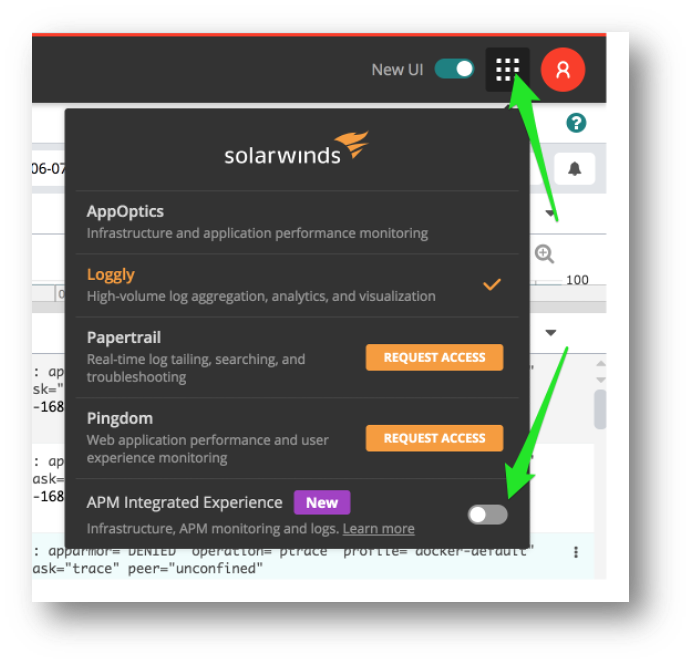
If you’re an existing AppOptics or Loggly user, use the app switcher in the top right to activate the new experience as seen below.
If you aren’t using SolarWinds monitoring products yet, sign up for a trial. All new trials will default into the integrated experience.