





Those of us who work in DevOps or system operations know that monitoring can be quite expensive. It’s not uncommon for the cost of monitoring a cloud server to be more than the cost of the server itself. Vendors often charge separately for monitoring the server, applications, and user experience. You’ll pay more to get better resolution or data retention. Requirements on data privacy or security require “Enterprise tier” plans. They might lure you in by offering a discount initially and then demand large increases after growing your volume, counting on lock-in to keep you from switching. All these costs can easily add up.
Making sacrifices on monitoring can affect your team and customers
Many companies are forced to make sacrifices by reducing observability to specific services or reducing data retention. The first to go are often integration or staging environments, then analytics and reporting systems, then support services like identity services, followed by legacy systems. They may even invest real engineering hours reducing the log output from production applications. The problem is that today’s services are more connected than ever. It’s not enough to just monitor one customer-facing system. There are a range of supporting services and dependencies, and a loss of availability can have unexpected downstream effects.
These sacrifices conclude in not having a complete picture when a critical incident arises. This can lead to longer outages, longer time to resolution, and result in major impact to customers. Your engineers may spend more valuable time troubleshooting problems due to the poor state of infrastructure. Without access to continuous monitoring data, the operations team must manually collect or backfill it to troubleshoot problems. In the worst case, data was not captured so you must reset the system without determining the root cause. Not only did your team spend time recovering the system, but it’s likely to happen again. If you’re operations team is spending a large portion of their time fighting fires, it can take time away from developing sustainable improvements and negatively affect morale.
You need visibility at several levels of your application stack, including your host metrics for capacity or scheduling problems, application metrics for performance issues in the code, database or network level, and custom metrics to identify problems in user experience. Sometimes issues are discovered and addressed immediately, but often you need enough data retention to look back several days or even several weeks to determine when the problem started.
Introducing AppOptics
Thankfully, a new breed of infrastructure and application monitoring solutions like SolarWinds® AppOptics™ provides you with affordable and comprehensive coverage. You can monitor all your servers and applications without choosing between them. Additionally, you don’t have to choose whether you can afford APM, infrastructure monitoring, or custom metrics.

AppOptics offers several unique advantages over the older generation of monitoring solutions. It’s built as a fully integrated system from the ground up. Rather than switching between multiple tabs for APM and host metrics, you can now see all those in a single dashboard, giving you an overview across your entire system.
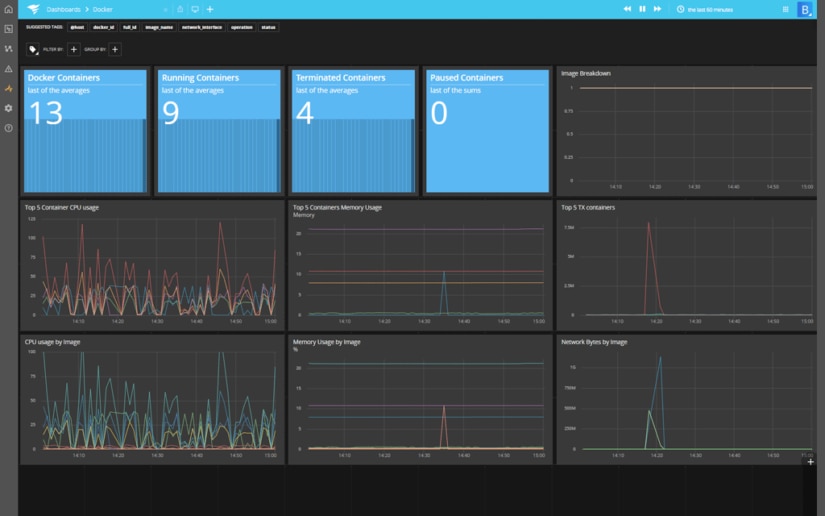
AppOptics also offers powerful features like distributed tracing, which is perfect for modern applications with microservices and n-tier architectures. Rather than monitoring each application as a separate silo, it will trace the connections between multiple services. This will allow you to better troubleshoot problems and performance issues in modern cloud-native applications.
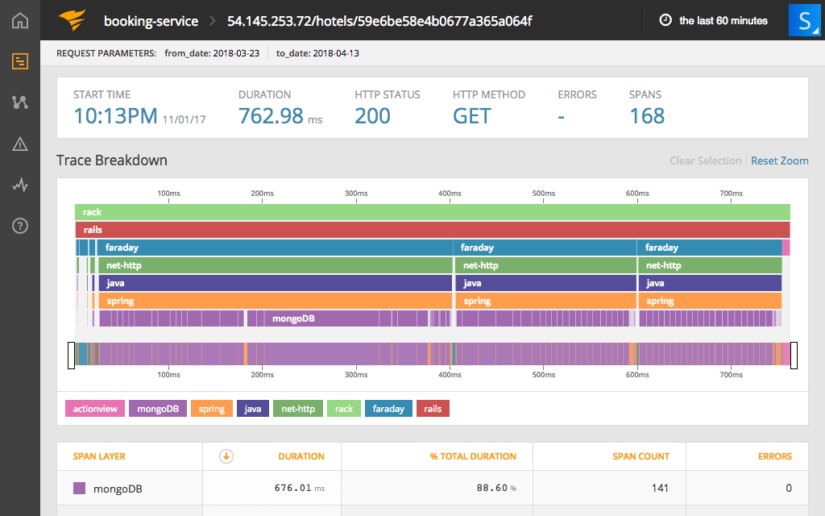
Stop reducing your observability due to cost and give yourself comprehensive coverage at an affordable price. Infrastructure monitoring starts at just $7.50/month and monitoring APM metrics at only $20/mo*. You can save tons of money over older generation monitoring solutions and have a better experience with a simpler workflow. Check it out today by signing up for a free trial.
*Pricing as of August 20th.







